Merge Sets
Version 1.1 of DI.Screening Analysis software can work with merge sets of Binding Affinity data from Affinity Screening. A merge set is the merged dataset of replicates of a Serial Dilution. In a merge set all data points obtained for all replicates measured for a certain Ligand are combined into one set that is fitted with a global fit to all data points. The software identifies replicates for a ligand by the following two parameters:
- Replicates have different Dilutionseries IDs signifying them as individually pipetted replicates
- Replicates share the same ligand name
Therefore it is advisable to always distinguish replicates from each other by Dilutionseries ID and not by assigning them distinct ligand names. To work with merge sets, the “Use Merge Sets” function in DI.Screening Analysis software must be activated:
The software then combines all dilution series found with the same ligand name into one merge set and automatically assigns numbers to the individual replicates:
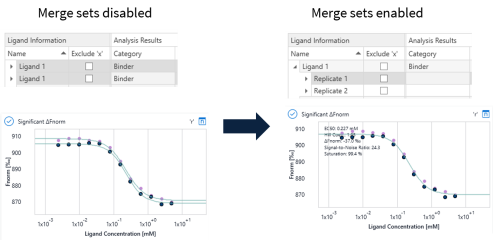
Note that the individual dilution series are also fitted individually but can be shown in the same plot using ‘shift’+select, when merge sets are disabled. As soon as merge sets are enabled the two replicates are combined in one merge set, which is approximated by a global fit to all data points. The individual replicates are labeled as “Replicate 1” and “Replicate 2” in the ligands table, while the merge set name is equivalent to the ligand name.
Note: It is important to note that Quality Checks can strongly depend on the context of how many data points are available. If for example replicates are analyzed individually and four wells out of a 12- point dilution series show aggregation, that has more influence on the Ligand Category than four wells showing aggregation in a triplicate dataset with 36 wells. That means that ligand categories or results of certain Quality Checks can differ depending on whether merge sets are enabled or disabled. Therefore it is strongly advised that it is decided at the start of a data analysis process if merge sets should be used or not.